Internet jest w punkcie zwrotnym. Ciągły wzrost blokowania reklam położył kres modelowi przychodów, który opiera się wyłącznie na reklamach w celu prowadzenia witryn i firm.
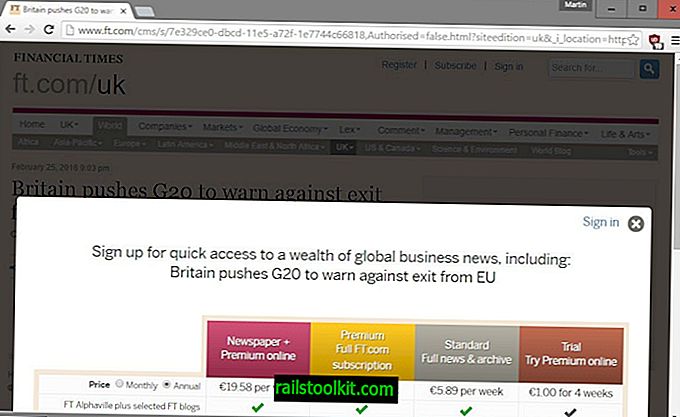
Szczególnie serwisy informacyjne zaczęły eksperymentować ze sposobami dywersyfikacji źródeł dochodów, a jedną z widocznych opcji, którą wdrożyły takie witryny jak The Wall Street Journal, Financial Times, New York Times czy Washington Post, jest system paywall.
Istnieją różne typy ścian płatnych, ale wszystkie mają wspólną cechę: blokują dostęp do treści bezpośrednio lub po przeczytaniu pewnej liczby artykułów na stronie.
Odwiedzający są następnie proszeni o zasubskrybowanie witryny, aby kontynuować czytanie artykułów na jej temat.
Może to mieć sens z biznesowego punktu widzenia i może być bardziej intratne niż walka z użytkownikami, którzy uruchamiają adblockery, ale ma to wadę zarówno dla strony z zapłatą, jak i zablokowanego użytkownika.
Witryny tracą wysoki odsetek odwiedzających, jeśli wdrożą system paywall. Nie jest jasne, jak wysoki jest ten odsetek, i prawdopodobnie zmienia się w zależności od witryny, ale prawdopodobnie jest znacznie wyższy niż odsetek odwiedzających, którzy subskrybują witrynę po przedstawieniu opcji subskrypcji, aby przeczytać żądany artykuł.
Zamaskuj swoją przeglądarkę
Nie jest tajemnicą, że serwisy informacyjne umożliwiają dostęp do agregatorów wiadomości i wyszukiwarek. Jeśli na przykład sprawdzisz Google News lub Wyszukaj, znajdziesz artykuły ze stron z wymienionymi tam ścianami płatnymi.
W przeszłości witryny z wiadomościami umożliwiały dostęp do odwiedzających pochodzących z głównych agregatorów wiadomości, takich jak Reddit, Digg czy Slashdot, ale obecnie taka praktyka wydaje się równie dobra, jak martwa.
Kolejna sztuczka polegająca na wklejeniu tytułu artykułu do wyszukiwarki w celu bezpośredniego przeczytania buforowanej historii nie działa już poprawnie, a artykuły na stronach z zapłatami nie są już zwykle buforowane.
Aktualizacja : Wall Street Journal ogłosił, że zatka dziurę opisaną poniżej. Nadal możesz czytać artykuły za zaporą witryny, używając następującej metody:
- Naciśnij klawisz F12, gdy znajdziesz się na stronie z odciętym artykułem i prośbą o zasubskrybowanie, aby przeczytać go w całości.
- Otwórz kartę konsoli.
- Wklej javascript: window.location = "// m.facebook.com/l.php?u="+encodeURIComponent(window.location.href);
- Wciśnij Enter.
Strona powinna zostać ponownie załadowana, a artykuł powinien zostać załadowany w całości. Możesz także opublikować link do artykułu na Facebooku, na przykład w nowym poście, który tylko Ty możesz zobaczyć. Kliknięcie opublikowanego linku powinno załadować artykuł w całości na stronie The Wall Street Journal.
Agent użytkownika i polecający
Prawdopodobnie zastanawiasz się, w jaki sposób witryny blokują lub umożliwiają dostęp do zawartości witryny. Metody te uległy poprawie na przestrzeni lat i nie wystarczy już po prostu zmienić stronę odsyłającą przeglądarki na //www.google.com/, aby uzyskać pełny dostęp do treści witryny.
Zamiast tego strony używają różnych kontroli, które obejmują klienta użytkownika, odnośniki i pliki cookie, a czasem nawet więcej, w celu ustalenia legalności dostępu.
Informacje ogólne
Prawdopodobnie najlepszym sposobem na maskowanie przeglądarki jest sprawienie, by wyglądała na Googlebota.
- Polecający: //www.google.com/
- User-Agent: Mozilla / 5.0 (kompatybilny; Googlebot / 2.1; + // www.google.com/bot.html
Firefox
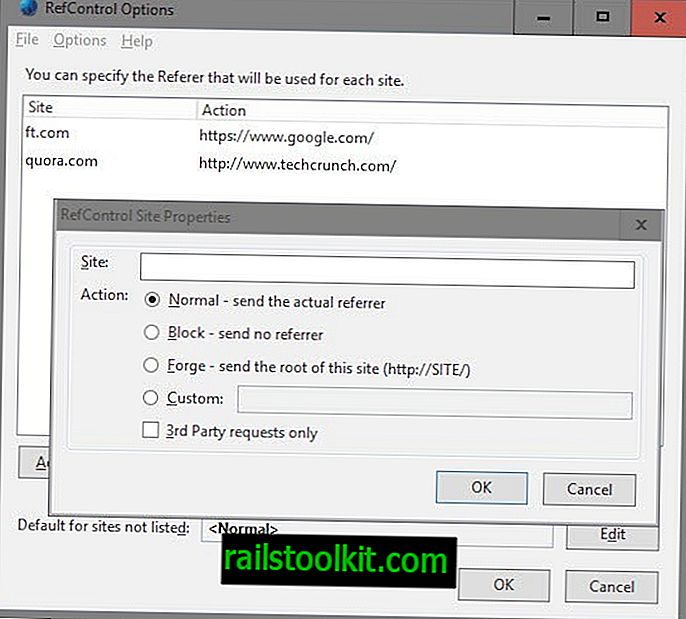
Użytkownicy Firefoksa potrzebują do tego dwóch dodatków do przeglądarki: pierwszego, RefControl, do zmiany wartości strony odsyłającej podczas odwiedzania serwisów informacyjnych, drugiego, User Agent Switcher, do zmiany agenta użytkownika przeglądarki.
- Pobierz i zainstaluj oba rozszerzenia w przeglądarce internetowej Firefox.
- Stuknij w klawisz Alt i wybierz Narzędzia> Opcje kontroli kontrolnej.
- Kliknij „dodaj witrynę”, wprowadź nazwę domeny w witrynie, wybierz akcję niestandardową i wprowadź //www.google.com/ jako stronę odsyłającą.
- Powtórz to dla wszystkich witryn z wiadomościami, do których chcesz uzyskać dostęp (niektóre mogą nie działać, nawet jeśli wprowadzisz zmiany, więc pamiętaj o tym).
- Po zakończeniu zamknij okno konfiguracji.
- Naciśnij ponownie klawisz Alt i wybierz z menu Narzędzia> Domyślny agent użytkownika> Edytuj agenty użytkownika.
- Wybierz Nowy> Agent użytkownika i zamień ciąg w polu Agent użytkownika na Mozilla / 5.0 (kompatybilny; Googlebot / 2.1; + // www.google.com/bot.html). Nazwij go Googlebot.
- Wyjdź z menu.
- Przed uzyskaniem dostępu do tych witryn dotknij Alt i wybierz Domyślny agent użytkownika> Googlebot.
To wszystko. Trochę niefortunne jest to, że nie ma rozszerzenia do przeglądarki Firefox, które automatycznie zmienia agenta użytkownika na podstawie odwiedzanych stron.
Google Chrome
Użytkownicy przeglądarki Google Chrome mogą instalować rozszerzenia takie jak User Agent Switcher i Referer Control, które są dostępne dla przeglądarki, aby zrobić to samo.
Istnieje jednak inna możliwość, a mianowicie utworzenie niestandardowego rozszerzenia, które automatyzuje proces w przeglądarce.
Instrukcje znajdują się na Elaineou. Zasadniczo wystarczy utworzyć nowy katalog na komputerze lokalnym, utworzyć w nim dwa pliki background.js i manifest.json, a także skopiować i wkleić do plików kod znaleziony na stronie.
Musisz włączyć „tryb programisty” na chrome: // extensions /, a następnie możesz wybrać „załaduj rozpakowane rozszerzenie”, aby wybrać folder, w którym utworzono dwa pliki, aby załadować rozszerzenie w Chrome.
Możesz zmodyfikować listę obsługiwanych witryn, aby dodać nowe.